Building Spark Applications
You can use Apache Maven to build Spark applications developed using Java and Scala.
For the Maven properties of CDH 5 components, see Using the CDH 5 Maven Repository. For the Maven properties of Kafka, see Maven Artifacts for Kafka.
Building Applications
Follow these best practices when building Spark Scala and Java applications:
- Compile against the same version of Spark that you are running.
- Build a single assembly JAR ("Uber" JAR) that includes all dependencies. In Maven, add the Maven assembly plug-in to build a JAR containing all dependencies:
<plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin>This plug-in manages the merge procedure for all available JAR files during the build. Exclude Spark, Hadoop, and Kafka (CDH 5.5 and higher) classes from the assembly JAR, because they are already available on the cluster and contained in the runtime classpath. In Maven, specify Spark, Hadoop, and Kafka dependencies with scope provided. For example:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.5.0-cdh5.5.0</version> <scope>provided</scope> </dependency>
Building Reusable Modules
Using existing Scala and Java classes inside the Spark shell requires an effective deployment procedure and dependency management. For simple and reliable reuse of Scala and Java classes and complete third-party libraries, you can use a module, which is a self-contained artifact created by Maven. This module can be shared by multiple users. This topic shows how to use Maven to create a module containing all dependencies.
Create a Maven Project
- Use Maven to generate the project directory:
$ mvn archetype:generate -DgroupId=com.mycompany -DartifactId=mylibrary \ -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
Download and Deploy Third-Party Libraries
- Prepare a location for all third-party libraries that are not available through Maven Central but are required for
the project:
$ mkdir libs $ cd libs
- Download the required artifacts.
- Use Maven to deploy the library JAR.
- Add the library to the dependencies section of the POM file.
- Repeat steps 2-4 for each library. For example, to add the JIDT library:
- Download and decompress the zip file:
$ curl http://lizier.me/joseph/software/jidt/download.php?file=infodynamics-dist-1.3.zip > infodynamics-dist.1.3.zip $ unzip infodynamics-dist-1.3.zip
- Deploy the library JAR:
$ mvn deploy:deploy-file \ -Durl=file:///HOME/.m2/repository -Dfile=libs/infodynamics.jar \ -DgroupId=org.jlizier.infodynamics -DartifactId=infodynamics -Dpackaging=jar -Dversion=1.3
- Add the library to the dependencies section of the POM file:
<dependency> <groupId>org.jlizier.infodynamics</groupId> <artifactId>infodynamics</artifactId> <version>1.3</version> </dependency>
- Download and decompress the zip file:
- Add the Maven assembly plug-in to the plugins section in the pom.xml file.
- Package the library JARs in a module:
$ mvn clean package
Run and Test the Spark Module
- Run the Spark shell, providing the module JAR in the --jars option:
$ spark-shell --jars target/mylibrary-1.0-SNAPSHOT-jar-with-dependencies.jar
- In the Environment tab of the Spark Web UI application (http://driver_host:4040/environment/), validate that the spark.jars property contains the library. For example:
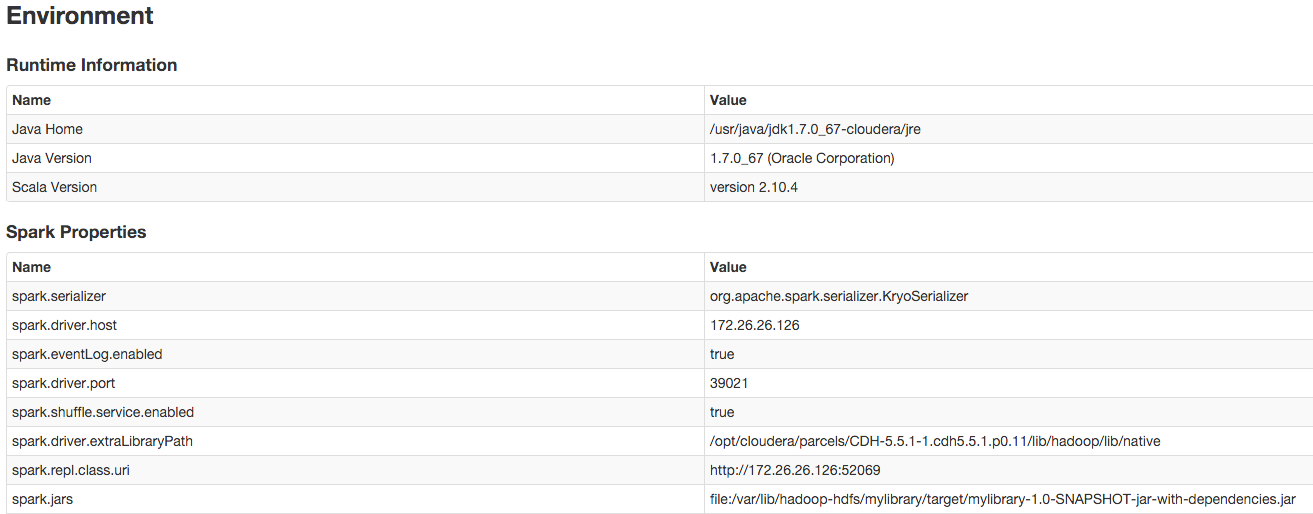
- In the Spark shell, test that you can import some of the required Java classes from the third-party library. For example, if you use the JIDT library, import MatrixUtils:
$ spark-shell ... scala> import infodynamics.utils.MatrixUtils;
Page generated July 8, 2016.
| << Accessing Parquet Files From Spark SQL Applications | ©2016 Cloudera, Inc. All rights reserved | Configuring Spark Applications >> |
| Terms and Conditions Privacy Policy |