Sentry Policy File Authorization
 Important: This is the documentation for configuring Sentry using the policy file
approach. Cloudera recommends you use the database-backed Sentry service introduced in CDH 5.1 to secure your data. See The Sentry Service for more information.
Important: This is the documentation for configuring Sentry using the policy file
approach. Cloudera recommends you use the database-backed Sentry service introduced in CDH 5.1 to secure your data. See The Sentry Service for more information.Sentry enables role-based, fine-grained authorization for HiveServer2, Cloudera Impala, and Cloudera Search.
- Prerequisites
- Terminology
- Privilege Model
- User to Group Mapping
- Policy File
- Sample Sentry Configuration Files
- Accessing Sentry-Secured Data Outside Hive/Impala
- Debugging Failed Sentry Authorization Requests
- Authorization Privilege Model for Hive and Impala
- Appendix: Authorization Privilege Model for Solr
The following topics provide instructions on how to install, upgrade, and configure policy file authorization.
Prerequisites
- CDH 4.3.0 or higher.
- HiveServer2 and the Hive Metastore running with strong authentication. For HiveServer2, strong authentication is either Kerberos or LDAP. For the Hive Metastore, only Kerberos is considered strong authentication (to override, see Securing the Hive Metastore).
- Impala 1.2.1 (or higher) running with strong authentication. With Impala, either Kerberos or LDAP can be configured to achieve strong authentication. Auditing of authentication failures is supported only with CDH 4.4.0 and Impala 1.2.1 or higher.
- Cloudera Search for CDH 5.1.0 or higher. Solr supports using Sentry beginning with CDH 5.1.0. Different functionality is added
at different releases:
- Sentry with policy files is added in CDH 5.1.0.
- Sentry with config support is added in CDH 5.5.0.
- Sentry with database-backed Sentry service is added with CDH 5.8.0.
- Kerberos authentication on your cluster. Kerberos prevent a user from bypassing the authorization system and gaining direct access to the underlying data.
Terminology
- An object is an entity protected by Sentry's authorization rules. The objects supported in the current release are server, database, table, URI, collection, and config.
- A role is a collection of rules for accessing a given object.
- A privilege is granted to a role to govern access to an object. With CDH 5.5, Sentry allows you to assign the SELECT privilege to
columns (only for Hive and Impala). Supported privileges are:
Table 1. Valid privilege types and the objects they apply to Privilege Object INSERT DB, TABLE SELECT DB, TABLE, COLUMN UPDATE COLLECTION, CONFIG QUERY COLLECTION, CONFIG ALL SERVER, TABLE, DB, URI, COLLECTION, CONFIG - A user is an entity that is permitted by the authentication subsystem to access the service. This entity can be a Kerberos principal, an LDAP userid, or an artifact of some other supported pluggable authentication system.
- A group connects the authentication system with the authorization system. It is a collection of one or more users who have been granted one or more authorization roles. Sentry allows a set of roles to be configured for a group.
- A configured group provider determines a user’s affiliation with a group. The current release supports HDFS-backed groups and locally configured groups.
Privilege Model
- Allows any user to execute show function, desc function, and show locks.
- Allows the user to see only those tables, databases, collections, configs for which this user has privileges.
- Requires a user to have the necessary privileges on the URI to execute HiveQL operations that take in a location. Examples of such operations include LOAD, IMPORT, and EXPORT.
- Privileges granted on URIs are recursively applied to all subdirectories. That is, privileges only need to be granted on the parent directory.
- CDH 5.5 introduces column-level access control for tables in Hive and Impala. Previously, Sentry supported privilege granularity only down to a table. Hence, if you wanted to restrict access to a column of sensitive data, the workaround would be to first create view for a subset of columns, and then grant privileges on that view. To reduce the administrative overhead associated with such an approach, Sentry now allows you to assign the SELECT privilege on a subset of columns in a table.
Important:
- When Sentry is enabled, you must use Beeline to execute Hive queries. Hive CLI is not supported with Sentry and must be disabled.
- When Sentry is enabled, a user with no privileges on a database will not be allowed to connect to HiveServer2. This is because the use <database> command is now executed as part of the connection to HiveServer2, which is why the connection fails. See HIVE-4256.
For more information, see Authorization Privilege Model for Hive and Impala and Appendix: Authorization Privilege Model for Solr.
Granting Privileges
 Note: In the following example(s),
server1 refers to an alias Sentry uses for the associated Hive service. It does not refer to any physical server. This alias can be modified using the hive.sentry.server property in hive-site.xml. If you are using Cloudera Manager, modify the Hive property, Server Name for Sentry Authorization, in
the category.
Note: In the following example(s),
server1 refers to an alias Sentry uses for the associated Hive service. It does not refer to any physical server. This alias can be modified using the hive.sentry.server property in hive-site.xml. If you are using Cloudera Manager, modify the Hive property, Server Name for Sentry Authorization, in
the category.server=server1->db=sales->table=customer->action=Select
sales_read = server=server1->db=sales->table=customers->column=Id->action=selectEach object must be specified as a hierarchy of the containing objects, from server to table, followed by the privilege granted for that object. A role can contain multiple such rules, separated by commas. For example, a role might contain the Select privilege for the customer and items tables in the sales database, and the Insert privilege for the sales_insights table in the reports database. You would specify this as follows:
sales_reporting = \ server=server1->db=sales->table=customer->action=Select, \ server=server1->db=sales->table=items->action=Select, \ server=server1->db=reports->table=sales_insights->action=Insert
User to Group Mapping
- Sentry - Groups are looked up on the host the Sentry Server runs on.
- Hive - Groups are looked up on the hosts running HiveServer2 and the Hive Metastore.
- Impala - Groups are looked up on the Catalog Server and on all of the Impala daemon hosts.
Group mappings in Sentry can be summarized as in the figure below:
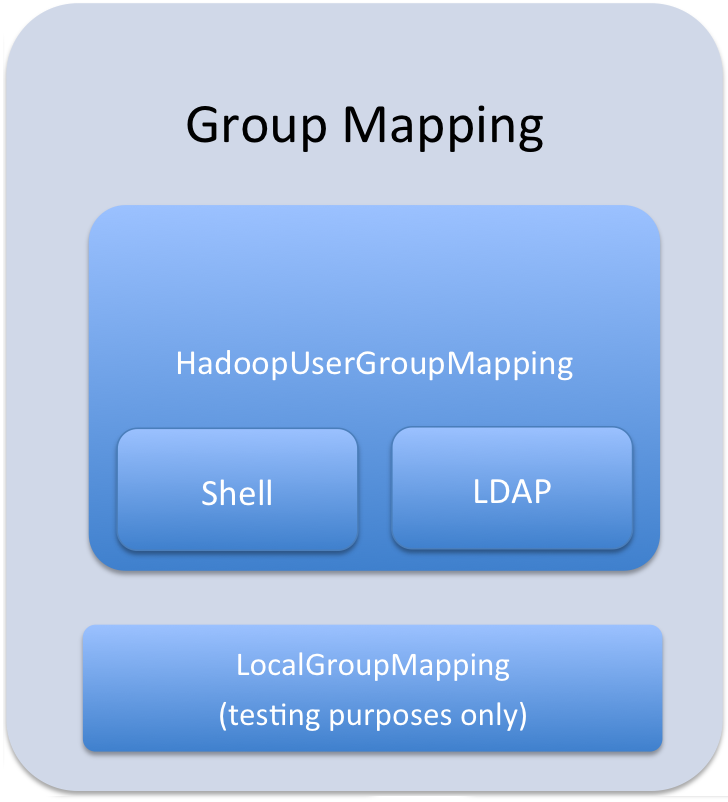
Important: You can use either Hadoop groups or local groups, but not both at the same
time. Local groups are traditionally used for a quick proof-of-concept, while Hadoop groups are more commonly used in production. Refer Configuring LDAP Group Mappings for details on configuring LDAP group mappings in Hadoop.Policy File
The sections that follow contain notes on creating and maintaining the policy file, and using URIs to load external data and JARs.
 Warning: An invalid policy file will be ignored while logging an exception. This will lead
to a situation where users will lose access to all Sentry-protected data, since default Sentry behavior is deny unless a user has been explicitly granted access. (Note that if
only the per-DB policy file is invalid, it will invalidate only the policies in that file.)
Warning: An invalid policy file will be ignored while logging an exception. This will lead
to a situation where users will lose access to all Sentry-protected data, since default Sentry behavior is deny unless a user has been explicitly granted access. (Note that if
only the per-DB policy file is invalid, it will invalidate only the policies in that file.)Storing the Policy File
Considerations for storing the policy file(s) in HDFS include:
- Replication count - Because the file is read for each query in Hive and read once every five minutes by all Impala daemons, you should increase this value; since it is a small file, setting the replication count equal to the number of client nodes in the cluster is reasonable.
- Updating the file - Updates to the file are reflected immediately, so you should write them to a temporary copy of the file first, and then replace the existing file with the temporary one after all the updates are complete. This avoids race conditions caused by reads on an incomplete file.
Defining Roles
role1 = privilege1 role1 = privilege2Role names are scoped to a specific file. For example, if you give role1 the ALL privilege on db1 in the global policy file and give role1 ALL on db2 in the per-db db2 policy file, the user will be given both privileges.
URIs
Any command which references a URI such as CREATE TABLE EXTERNAL, LOAD, IMPORT, EXPORT, and more, in addition to CREATE TEMPORARY FUNCTION requires the URI privilege. This is an important security control because without this users could simply create an external table over an existing table they do not have access to and bypass Sentry.
URIs must start with either hdfs:// or file://. If a URI starts with anything else, it will cause an exception and the policy file will be invalid.
data_read = server=server1->uri=file:///path/to/dir,\ server=server1->uri=hdfs://namenode:port/path/to/dir
Important: Because the NameNode host and port must be specified, Cloudera strongly
recommends you use High Availability (HA). This ensures that the URI will remain constant even if the NameNode changes.Loading Data
- Load data from a local/NFS directory:
server=server1->uri=file:///path/to/nfs/local/to/nfs
- Load data from HDFS (MapReduce, Pig, and so on):
server=server1->uri=hdfs://ha-nn-uri/data/landing-skid
In addition to the privilege in Sentry, the hive or impala user will require the appropriate file permissions to access the data being loaded. Groups can be used for this purpose. For example, create a group hive-users, and add the hive and impala users along with the users who will be loading data, to this group.
$ groupadd hive-users $ usermod -G someuser,hive-users someuser $ usermod -G hive,hive-users hive
External Tables
External tables require the ALL@database privilege in addition to the URI privilege. When data is being inserted through the EXTERNAL TABLE statement, or is referenced from an HDFS location outside the normal Hive database directories, the user needs appropriate permissions on the URIs corresponding to those HDFS locations. This means that the URI location must either be owned by the hive:hive user OR the hive/impala users must be members of the group that owns the directory.
[roles] someuser_home_dir_role = server=server1->uri=hdfs://ha-nn-uri/user/someuserYou should now be able to create an external table:
CREATE EXTERNAL TABLE ... LOCATION 'hdfs://ha-nn-uri/user/someuser/mytable';
Sample Sentry Configuration Files
This section provides a sample configuration.
Note: In the following example(s),
server1 refers to an alias Sentry uses for the associated Hive service. It does not refer to any physical server. This alias can be modified using the hive.sentry.server property in hive-site.xml. If you are using Cloudera Manager, modify the Hive property, Server Name for Sentry Authorization, in
the category.Policy Files
The following is an example of a policy file with a per-DB policy file. In this example, the first policy file, sentry-provider.ini would exist in HDFS; hdfs://ha-nn-uri/etc/sentry/sentry-provider.ini might be an appropriate location. The per-DB policy file is for the customer's database. It is located at hdfs://ha-nn-uri/etc/sentry/customers.ini.
[databases]
# Defines the location of the per DB policy file for the customers DB/schema
customers = hdfs://ha-nn-uri/etc/sentry/customers.ini
[groups]
# Assigns each Hadoop group to its set of roles
manager = analyst_role, junior_analyst_role
analyst = analyst_role
jranalyst = junior_analyst_role
customers_admin = customers_admin_role
admin = admin_role
[roles]
# The uris below define a define a landing skid which
# the user can use to import or export data from the system.
# Since the server runs as the user "hive" files in that directory
# must either have the group hive and read/write set or
# be world read/write.
analyst_role = server=server1->db=analyst1, \
server=server1->db=jranalyst1->table=*->action=select
server=server1->uri=hdfs://ha-nn-uri/landing/analyst1
junior_analyst_role = server=server1->db=jranalyst1, \
server=server1->uri=hdfs://ha-nn-uri/landing/jranalyst1
# Implies everything on server1 -> customers. Privileges for
# customers can be defined in the global policy file even though
# customers has its only policy file. Note that the Privileges from
# both the global policy file and the per-DB policy file
# are merged. There is no overriding.
customers_admin_role = server=server1->db=customers
# Implies everything on server1.
admin_role = server=server1[groups] manager = customers_insert_role, customers_select_role analyst = customers_select_role [roles] customers_insert_role = server=server1->db=customers->table=*->action=insert customers_select_role = server=server1->db=customers->table=*->action=select
Important: Sentry does not support using the view
keyword in policy files. If you want to define a role against a view, use the keyword table instead. For example, to define the role analyst_role against the view col_test_view:
[roles] analyst_role = server=server1->db=default->table=col_test_view->action=select
Sentry Configuration File
The following is an example of a sentry-site.xml file.
Important: If you are using Cloudera Manager 4.6 (or lower), make sure you
do not store sentry-site.xml in /etc/hive/conf ; that directory is regenerated whenever the Hive client
configurations are redeployed. Instead, use a directory such as /etc/sentry to store the sentry file.
If you are using Cloudera Manager 4.7 (or higher), Cloudera Manager will create and deploy sentry-site.xml for you.See The Sentry Service for more details on configuring Sentry with Cloudera Manager.
sentry-site.xml
<configuration>
<property>
<name>hive.sentry.provider</name>
<value>org.apache.sentry.provider.file.HadoopGroupResourceAuthorizationProvider</value>
</property>
<property>
<name>hive.sentry.provider.resource</name>
<value>/path/to/authz-provider.ini</value>
<!--
If the hdfs-site.xml points to HDFS, the path will be in HDFS;
alternatively you could specify a full path, e.g.:
hdfs://namenode:port/path/to/authz-provider.ini
file:///path/to/authz-provider.ini
-->
</property>
<property>
<name>sentry.hive.server</name>
<value>server1</value>
</property>
</configuration>
Accessing Sentry-Secured Data Outside Hive/Impala
Note: Cloudera strongly recommends you use Hive/Impala SQL queries to access data secured by Sentry,
as opposed to accessing the data files directly.However, there are scenarios where fully vetted and reviewed jobs will also need to access the data stored in the Hive warehouse. A typical scenario would be a secured MapReduce transformation job that is executed automatically as an application user. In such cases it's important to know that the user executing this job will also have full access to the data in the Hive warehouse.
Scenario One: Authorizing Jobs
Problem
A reviewed, vetted, and automated job requires access to the Hive warehouse and cannot use Hive/Impala to access the data.
Solution
Create a group which contains hive, impala, and the user executing the automated job. For example, if the etl user is executing the automated job, you can create a group called hive-users which contains the hive, impala, and etl users.
$ groupadd hive-users $ usermod -G hive,impala,hive-users hive $ usermod -G hive,impala,hive-users impala $ usermod -G etl,hive-users etlOnce you have added users to the hive-users group, change directory permissions in the HDFS:
$ hadoop fs -chgrp -R hive:hive-users /user/hive/warehouse $ hadoop fs -chmod -R 770 /user/hive/warehouse
Scenario Two: Authorizing Group Access to Databases
Problem
One group of users, grp1 should have full access to the database, db1, outside of Sentry. The database, db1 should not be accessible to any other groups, outside of Sentry. Sentry should be used for all other authorization needs.
Solution
$ usermod -G hive,impala,grp1 hive $ usermod -G hive,impala,grp1 impalaThen change group ownerships of all directories and files in db1 to grp1, and modify directory permissions in the HDFS. This example is only applicable to local groups on a single host.
$ hadoop fs -chgrp -R hive:grp1 /user/hive/warehouse/db1.db $ hadoop fs -chmod -R 770 /user/hive/warehouse/db1.db
Debugging Failed Sentry Authorization Requests
- In Cloudera Manager, add log4j.logger.org.apache.sentry=DEBUG to the logging settings for your service through the corresponding Logging Safety Valve field for the Impala, Hive Server 2, or Solr Server services.
- On systems not managed by Cloudera Manager, add log4j.logger.org.apache.sentry=DEBUG to the log4j.properties file on each host in the cluster, in the appropriate configuration directory for each service.
FilePermission server..., RequestPermission server...., result [true|false]which indicate each evaluation Sentry makes. The FilePermission is from the policy file, while RequestPermission is the privilege required for the query. A RequestPermission will iterate over all appropriate FilePermission settings until a match is found. If no matching privilege is found, Sentry returns false indicating "Access Denied" .
Authorization Privilege Model for Hive and Impala
Privileges can be granted on different objects in the Hive warehouse. Any privilege that can be granted is associated with a level in the object hierarchy. If a privilege is granted on a container object in the hierarchy, the base object automatically inherits it. For instance, if a user has ALL privileges on the database scope, then (s)he has ALL privileges on all of the base objects contained within that scope.
Object Hierarchy in Hive
Server
Database
Table
Partition
Columns
View
Index
Function/Routine
Lock
| Privilege | Object |
|---|---|
| INSERT | DB, TABLE |
| SELECT | DB, TABLE, COLUMN |
| ALL | SERVER, TABLE, DB, URI |
| Base Object | Granular privileges on object | Container object that contains the base object | Privileges on container object that implies privileges on the base object |
|---|---|---|---|
| DATABASE | ALL | SERVER | ALL |
| TABLE | INSERT | DATABASE | ALL |
| TABLE | SELECT | DATABASE | ALL |
| COLUMN | SELECT | DATABASE | ALL |
| VIEW | SELECT | DATABASE | ALL |
| Operation | Scope | Privileges Required | URI |
|---|---|---|---|
| CREATE DATABASE | SERVER | ALL | |
| DROP DATABASE | DATABASE | ALL | |
| CREATE TABLE | DATABASE | ALL | |
| DROP TABLE | TABLE | ALL | |
| CREATE VIEW
-This operation is allowed if you have column-level SELECT access to the columns being used. |
DATABASE; SELECT on TABLE; | ALL | |
| ALTER VIEW
-This operation is allowed if you have column-level SELECT access to the columns being used. |
VIEW/TABLE | ALL | |
| DROP VIEW | VIEW/TABLE | ALL | |
| ALTER TABLE .. ADD COLUMNS | TABLE | ALL on DATABASE | |
| ALTER TABLE .. REPLACE COLUMNS | TABLE | ALL on DATABASE | |
| ALTER TABLE .. CHANGE column | TABLE | ALL on DATABASE | |
| ALTER TABLE .. RENAME | TABLE | ALL on DATABASE | |
| ALTER TABLE .. SET TBLPROPERTIES | TABLE | ALL on DATABASE | |
| ALTER TABLE .. SET FILEFORMAT | TABLE | ALL on DATABASE | |
| ALTER TABLE .. SET LOCATION | TABLE | ALL on DATABASE | URI |
| ALTER TABLE .. ADD PARTITION | TABLE | ALL on DATABASE | |
| ALTER TABLE .. ADD PARTITION location | TABLE | ALL on DATABASE | URI |
| ALTER TABLE .. DROP PARTITION | TABLE | ALL on DATABASE | |
| ALTER TABLE .. PARTITION SET FILEFORMAT | TABLE | ALL on DATABASE | |
| SHOW CREATE TABLE | TABLE | SELECT/INSERT | |
| SHOW PARTITIONS | TABLE | SELECT/INSERT | |
| SHOW TABLES
-Output includes all the tables for which the user has table-level privileges and all the tables for which the user has some column-level privileges. |
TABLE | SELECT/INSERT | |
| SHOW GRANT ROLE
-Output includes an additional field for any column-level privileges. |
TABLE | SELECT/INSERT | |
| DESCRIBE TABLE
-Output shows all columns if the user has table level-privileges or SELECT privilege on at least one table column |
TABLE | SELECT/INSERT | |
| LOAD DATA | TABLE | INSERT | URI |
| SELECT
-You can grant the SELECT privilege on a view to give users access to specific columns of a table they do not otherwise have access to. -See Column-level Authorization for details on allowed column-level operations. |
VIEW/TABLE; COLUMN | SELECT | |
| INSERT OVERWRITE TABLE | TABLE | INSERT | |
| CREATE TABLE .. AS SELECT
-This operation is allowed if you have column-level SELECT access to the columns being used. |
DATABASE; SELECT on TABLE | ALL | |
| USE <dbName> | Any | ||
| CREATE FUNCTION | SERVER | ALL | |
| ALTER TABLE .. SET SERDEPROPERTIES | TABLE | ALL on DATABASE | |
| ALTER TABLE .. PARTITION SET SERDEPROPERTIES | TABLE | ALL on DATABASE | |
| Hive-Only Operations | |||
| INSERT OVERWRITE DIRECTORY | TABLE | INSERT | URI |
| Analyze TABLE | TABLE | SELECT + INSERT | |
| IMPORT TABLE | DATABASE | ALL | URI |
| EXPORT TABLE | TABLE | SELECT | URI |
| ALTER TABLE TOUCH | TABLE | ALL on DATABASE | |
| ALTER TABLE TOUCH PARTITION | TABLE | ALL on DATABASE | |
| ALTER TABLE .. CLUSTERED BY SORTED BY | TABLE | ALL on DATABASE | |
| ALTER TABLE .. ENABLE/DISABLE | TABLE | ALL on DATABASE | |
| ALTER TABLE .. PARTITION ENABLE/DISABLE | TABLE | ALL on DATABASE | |
| ALTER TABLE .. PARTITION.. RENAME TO PARTITION | TABLE | ALL on DATABASE | |
| MSCK REPAIR TABLE | TABLE | ALL | |
| ALTER DATABASE | DATABASE | ALL | |
| DESCRIBE DATABASE | DATABASE | SELECT/INSERT | |
| SHOW COLUMNS
-Output for this operation filters columns to which the user does not have explicit SELECT access |
TABLE | SELECT/INSERT | |
| CREATE INDEX | TABLE | ALL | |
| DROP INDEX | TABLE | ALL | |
| SHOW INDEXES | TABLE | SELECT/INSERT | |
| GRANT PRIVILEGE | Allowed only for Sentry admin users | ||
| REVOKE PRIVILEGE | Allowed only for Sentry admin users | ||
| SHOW GRANTS | Allowed only for Sentry admin users | ||
| SHOW TBLPROPERTIES | TABLE | SELECT/INSERT | |
| DESCRIBE TABLE .. PARTITION | TABLE | SELECT/INSERT | |
| ADD JAR | Not Allowed | ||
| ADD FILE | Not Allowed | ||
| DFS | Not Allowed | ||
| Impala-Only Operations | |||
| EXPLAIN | TABLE; COLUMN | SELECT | |
| INVALIDATE METADATA | SERVER | ALL | |
| INVALIDATE METADATA <table name> | TABLE | SELECT/INSERT | |
| REFRESH <table name> | TABLE | SELECT/INSERT | |
| DROP FUNCTION | SERVER | ALL | |
| COMPUTE STATS | TABLE | ALL | |
Appendix: Authorization Privilege Model for Solr
The tables below refer to the request handlers defined in the generated solrconfig.xml.secure. If you are not using this configuration file, the below may not apply.
admin is a special collection in sentry used to represent administrative actions. A non-administrative request may only require privileges on the collection or config on which the request is being performed. This is called either collection1 or config1 in this appendix. An administrative request may require privileges on both the admin collection and collection1. This is denoted as admin, collection1 in the tables below.
Note: If no privileges are
granted, no access is possible. For example, accessing the Solr Admin UI requires the QUERY privilege. If no users are granted the QUERY
privilege, no access to the Solr Admin UI is possible.| Request Handler | Required Collection Privilege | Collections that Require Privilege |
|---|---|---|
| select | QUERY | collection1 |
| query | QUERY | collection1 |
| get | QUERY | collection1 |
| browse | QUERY | collection1 |
| tvrh | QUERY | collection1 |
| clustering | QUERY | collection1 |
| terms | QUERY | collection1 |
| elevate | QUERY | collection1 |
| analysis/field | QUERY | collection1 |
| analysis/document | QUERY | collection1 |
| update | UPDATE | collection1 |
| update/json | UPDATE | collection1 |
| update/csv | UPDATE | collection1 |
| Collection Action | Required Collection Privilege | Collections that Require Privilege |
|---|---|---|
| create | UPDATE | admin, collection1 |
| delete | UPDATE | admin, collection1 |
| reload | UPDATE | admin, collection1 |
| createAlias | UPDATE | admin, collection1
Note: collection1 here refers to the name of the alias, not the
underlying collection(s). For example, http://YOUR-HOST:8983/ solr/admin/collections?action= CREATEALIAS&name=collection1
&collections=underlyingCollection |
| deleteAlias | UPDATE | admin, collection1
Note: collection1 here refers to the name of the alias, not the
underlying collection(s). For example, http://YOUR-HOST:8983/ solr/admin/collections?action= DELETEALIAS&name=collection1 |
| syncShard | UPDATE | admin, collection1 |
| splitShard | UPDATE | admin, collection1 |
| deleteShard | UPDATE | admin, collection1 |
| Collection Action | Required Collection Privilege | Collections that Require Privilege |
|---|---|---|
| create | UPDATE | admin, collection1 |
| rename | UPDATE | admin, collection1 |
| load | UPDATE | admin, collection1 |
| unload | UPDATE | admin, collection1 |
| status | UPDATE | admin, collection1 |
| persist | UPDATE | admin |
| reload | UPDATE | admin, collection1 |
| swap | UPDATE | admin, collection1 |
| mergeIndexes | UPDATE | admin, collection1 |
| split | UPDATE | admin, collection1 |
| prepRecover | UPDATE | admin, collection1 |
| requestRecover | UPDATE | admin, collection1 |
| requestSyncShard | UPDATE | admin, collection1 |
| requestApplyUpdates | UPDATE | admin, collection1 |
| Request Handler | Required Collection Privilege | Collections that Require Privilege |
|---|---|---|
| LukeRequestHandler | QUERY | admin |
| SystemInfoHandler | QUERY | admin |
| SolrInfoMBeanHandler | QUERY | admin |
| PluginInfoHandler | QUERY | admin |
| ThreadDumpHandler | QUERY | admin |
| PropertiesRequestHandler | QUERY | admin |
| LogginHandler | QUERY, UPDATE (or *) | admin |
| ShowFileRequestHandler | QUERY | admin |
| Config Action | Required Collection Privilege | Collections that Require Privilege | Required Config Privilege | Configs that Require Privilege |
|---|---|---|---|---|
| CREATE | UPDATE | admin | * | config1 |
| DELETE | UPDATE | admin | * | config1 |
| << Using the Sentry Web Server | ©2016 Cloudera, Inc. All rights reserved | Installing and Upgrading Sentry for Policy File Authorization >> |
| Terms and Conditions Privacy Policy |