Accessing Data Stored in Amazon S3
To access data stored in Amazon S3 from Spark applications, you use Hadoop file APIs (SparkContext.hadoopFile, JavaHadoopRDD.saveAsHadoopFile, SparkContext.newAPIHadoopRDD, and JavaHadoopRDD.saveAsNewAPIHadoopFile) for reading and writing RDDs, providing URLs of the form s3a://bucket_name/path/to/file. You can read and write Spark SQL DataFrames using the Data Source API.
You can access Amazon S3 by the following methods:
- Without credentials - Run EC2 instances with instance profiles associated with IAM roles that have the permissions you want. Requests from a machine with such a profile authenticate without credentials.
- With credentials
- Specify the credentials in a configuration file, such as core-site.xml:
<property> <name>fs.s3a.access.key</name> <value>...</value> </property> <property> <name>fs.s3a.secret.key</name> <value>...</value> </property> - Specify the credentials at run time. For example:
sc.hadoopConfiguration.set("fs.s3a.access.key", "...") sc.hadoopConfiguration.set("fs.s3a.secret.key", "...")
- Specify the credentials in a configuration file, such as core-site.xml:
Reading and Writing Text Files From and To Amazon S3
After specifying credentials:
scala> sc.hadoopConfiguration.set("fs.s3a.access.key", "...")
scala> sc.hadoopConfiguration.set("fs.s3a.secret.key", "...")
you can perform the word count application:
scala> val sonnets = sc.textFile("s3a://s3-to-ec2/sonnets.txt")
scala> val counts = sonnets.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
scala> counts.saveAsTextFile("s3a://s3-to-ec2/output")
on a sonnets.txt file stored in Amazon S3:
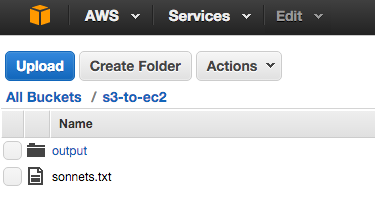
Yielding the output:
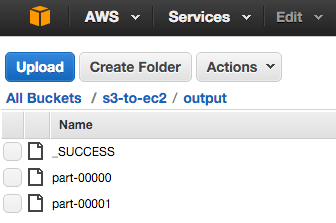
Reading and Writing Data Sources From and To Amazon S3
The following example illustrates how to read a text file from Amazon S3 into an RDD, convert the RDD to a DataFrame, and then use the Data Source API to write the DataFrame into a Parquet file on Amazon S3:- Specify Amazon S3 credentials:
scala> sc.hadoopConfiguration.set("fs.s3a.access.key", "...") scala> sc.hadoopConfiguration.set("fs.s3a.secret.key", "...") - Read a text file in Amazon S3:
scala> val sample_07 = sc.textFile("s3a://s3-to-ec2/sample_07.csv") - Map lines into columns:
scala> import org.apache.spark.sql.Row scala> val rdd_07 = sample_07.map(_.split('\t')).map(e ⇒ Row(e(0), e(1), e(2).trim.toInt, e(3).trim.toInt)) - Create a schema and apply to the RDD to create a DataFrame:
scala> import org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType}; scala> val schema = StructType(Array( StructField("code",StringType,false), StructField("description",StringType,false), StructField("total_emp",IntegerType,false), StructField("salary",IntegerType,false))) scala> val df_07 = sqlContext.createDataFrame(rdd_07,schema) - Write DataFrame to a Parquet file:
scala> df_07.write.parquet("s3a://s3-to-ec2/sample_07.parquet")
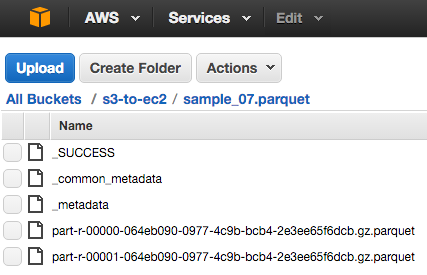
The files are compressed with the default gzip compression.
Page generated July 8, 2016.
| << Accessing External Storage | ©2016 Cloudera, Inc. All rights reserved | Accessing Avro Data Files From Spark SQL Applications >> |
| Terms and Conditions Privacy Policy |