Apache Impala (incubating) Overview
Impala provides fast, interactive SQL queries directly on your Apache Hadoop data stored in HDFS, HBase, or the Amazon Simple Storage Service (S3). In addition to using the same unified storage platform, Impala also uses the same metadata, SQL syntax (Hive SQL), ODBC driver, and user interface (Impala query UI in Hue) as Apache Hive. This provides a familiar and unified platform for real-time or batch-oriented queries.
Impala is an addition to tools available for querying big data. Impala does not replace the batch processing frameworks built on MapReduce such as Hive. Hive and other frameworks built on MapReduce are best suited for long running batch jobs, such as those involving batch processing of Extract, Transform, and Load (ETL) type jobs.
 Note: Impala was accepted into the Apache incubator on December 2, 2015. In places where the
documentation formerly referred to "Cloudera Impala", now the official name is "Apache Impala (incubating)".
Note: Impala was accepted into the Apache incubator on December 2, 2015. In places where the
documentation formerly referred to "Cloudera Impala", now the official name is "Apache Impala (incubating)".Impala Benefits
- Familiar SQL interface that data scientists and analysts already know.
- Ability to query high volumes of data ("big data") in Apache Hadoop.
- Distributed queries in a cluster environment, for convenient scaling and to make use of cost-effective commodity hardware.
- Ability to share data files between different components with no copy or export/import step; for example, to write with Pig, transform with Hive and query with Impala. Impala can read from and write to Hive tables, enabling simple data interchange using Impala for analytics on Hive-produced data.
- Single system for big data processing and analytics, so customers can avoid costly modeling and ETL just for analytics.
How Impala Works with CDH
The following graphic illustrates how Impala is positioned in the broader Cloudera environment:
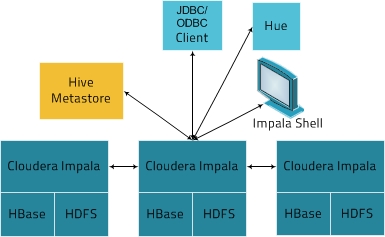
- Clients - Entities including Hue, ODBC clients, JDBC clients, and the Impala Shell can all interact with Impala. These interfaces are typically used to issue queries or complete administrative tasks such as connecting to Impala.
- Hive Metastore - Stores information about the data available to Impala. For example, the metastore lets Impala know what databases are available and what the structure of those databases is. As you create, drop, and alter schema objects, load data into tables, and so on through Impala SQL statements, the relevant metadata changes are automatically broadcast to all Impala nodes by the dedicated catalog service introduced in Impala 1.2.
- Impala - This process, which runs on DataNodes, coordinates and executes queries. Each instance of Impala can receive, plan, and coordinate queries from Impala clients. Queries are distributed among Impala nodes, and these nodes then act as workers, executing parallel query fragments.
- HBase and HDFS - Storage for data to be queried.
- User applications send SQL queries to Impala through ODBC or JDBC, which provide standardized querying interfaces. The user application may connect to any impalad in the cluster. This impalad becomes the coordinator for the query.
- Impala parses the query and analyzes it to determine what tasks need to be performed by impalad instances across the cluster. Execution is planned for optimal efficiency.
- Services such as HDFS and HBase are accessed by local impalad instances to provide data.
- Each impalad returns data to the coordinating impalad, which sends these results to the client.
Primary Impala Features
- Most common SQL-92 features of Hive Query Language (HiveQL) including SELECT, joins, and aggregate functions.
- HDFS, HBase, and Amazon Simple Storage System (S3) storage, including:
- HDFS file formats: Text file, SequenceFile, RCFile, Avro file, and Parquet.
- Compression codecs: Snappy, GZIP, Deflate, BZIP.
- Common data access interfaces including:
- JDBC driver.
- ODBC driver.
- Hue Beeswax and the Impala Query UI.
- Impala command-line interface.
- Kerberos authentication.
| << CDH Overview | ©2016 Cloudera, Inc. All rights reserved | Cloudera Search Overview >> |
| Terms and Conditions Privacy Policy |