Configuration Overview
When Cloudera Manager configures a service, it allocates roles that are required for that service to the hosts in your cluster. The role determines which service daemons run on a host.
- One host to run the NameNode role.
- One host to run as the secondary NameNode role.
- One host to run the Balancer role.
- Remaining hosts as to run DataNode roles.
A role group is a set of configuration properties for a role type, as well as a list of role instances associated with that group. Cloudera Manager automatically creates a default role group named Role Type Default Group for each role type.
When you run the installation or upgrade wizard, Cloudera Manager configures the default role groups it adds, and adds any other required role groups for a given role type. For example, a DataNode role on the same host as the NameNode might require a different configuration than DataNode roles running on other hosts. Cloudera Manager creates a separate role group for the DataNode role running on the NameNode host and uses the default configuration for DataNode roles running on other hosts.
Cloudera Manager wizards autoconfigure role group properties based on the resources available on the hosts. For properties that are not dependent on host resources, Cloudera Manager default values typically align with CDH default values for that configuration. Cloudera Manager deviates when the CDH default is not a recommended configuration or when the default values are illegal. For the complete catalog of properties and their default values, see Cloudera Manager Configuration Properties.
Server and Client Configuration
Administrators are sometimes surprised that modifying /etc/hadoop/conf and then restarting HDFS has no effect. That is because service instances started by Cloudera Manager do not read configurations from the default locations. To use HDFS as an example, when not managed by Cloudera Manager, there would usually be one HDFS configuration per host, located at /etc/hadoop/conf/hdfs-site.xml. Server-side daemons and clients running on the same host would all use that same configuration.
Cloudera Manager distinguishes between server and client configuration. In the case of HDFS, the file /etc/hadoop/conf/hdfs-site.xml contains only configuration relevant to an HDFS client. That is, by default, if you run a program that needs to communicate with Hadoop, it will get the addresses of the NameNode and JobTracker, and other important configurations, from that directory. A similar approach is taken for /etc/hbase/conf and /etc/hive/conf.
$ tree -a /var/run/cloudera-scm-Agent/process/879-hdfs-NAMENODE/ /var/run/cloudera-scm-Agent/process/879-hdfs-NAMENODE/ ├── cloudera_manager_Agent_fencer.py ├── cloudera_manager_Agent_fencer_secret_key.txt ├── cloudera-monitor.properties ├── core-site.xml ├── dfs_hosts_allow.txt ├── dfs_hosts_exclude.txt ├── event-filter-rules.json ├── hadoop-metrics2.properties ├── hdfs.keytab ├── hdfs-site.xml ├── log4j.properties ├── logs │ ├── stderr.log │ └── stdout.log ├── topology.map └── topology.py
- Sensitive information in the server-side configuration, such as the password for the Hive Metastore RDBMS, is not exposed to the clients.
- A service that depends on another service may deploy with customized configuration. For example, to get good HDFS read performance, Impala needs a specialized version of the HDFS client configuration, which may be harmful to a generic client. This is achieved by separating the HDFS configuration for the Impala daemons (stored in the per-process directory mentioned above) from that of the generic client (/etc/hadoop/conf).
- Client configuration files are much smaller and more readable. This also avoids confusing non-administrator Hadoop users with irrelevant server-side properties.
Cloudera Manager Configuration Layout
After running the Installation wizard, use Cloudera Manager to reconfigure the existing services and add and configure additional hosts and services.
- If you switch to the classic layout, Cloudera Manager preserves that setting when you upgrade to a new version.
- Selections made in one layout are not preserved when you switch.
- Certain features, including controls for configuring Navigator audit events and HDFS log redaction, are supported only in the new layout.
New layout pages contain controls that allow you to filter configuration properties based on configuration status, category, and group. For example, to display the JournalNode maximum log size property (JournalNode Max Log Size), click the and filters:
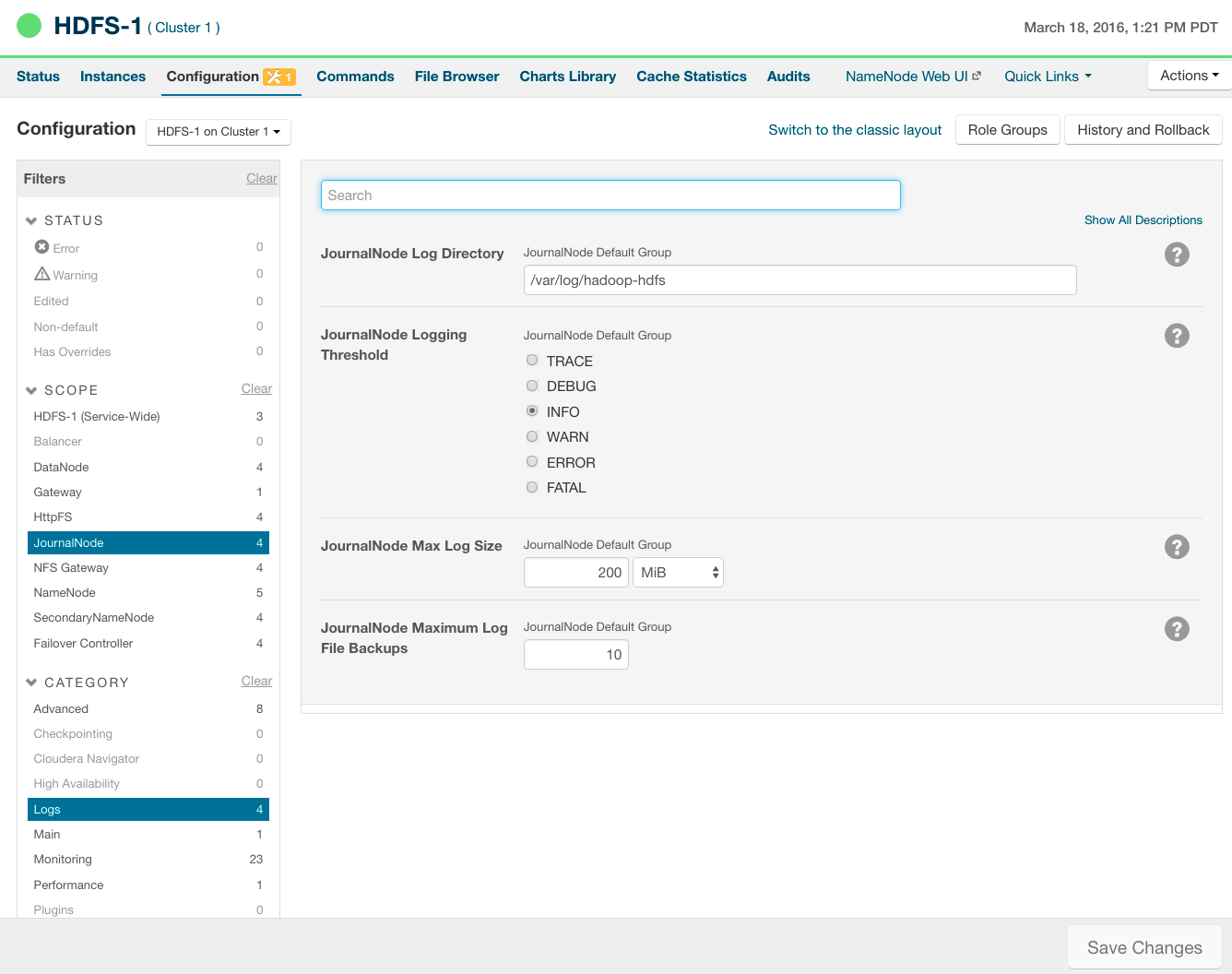
When a configuration property has been set to a value different from the default, a reset to default value icon  displays.
displays.
Classic layout pages are organized by role group and categories within the role group. For example, to display the JournalNode maximum log size property (JournalNode Max Log Size), select .
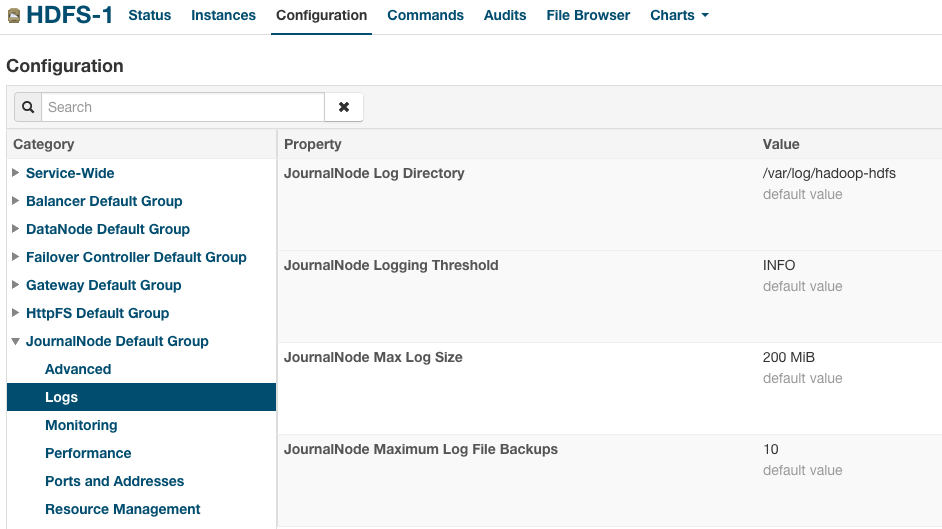
When a configuration property has been set to a value different from the default, a Reset to the default value link displays.
There is no mechanism for resetting to an autoconfigured value. However, you can use the configuration history and rollback feature to revert any configuration changes.
Continue reading:
| << Managing CDH and Managed Services Using Cloudera Manager | ©2016 Cloudera, Inc. All rights reserved | Modifying Configuration Properties Using Cloudera Manager >> |
| Terms and Conditions Privacy Policy |